Workflow
As said, this initiative will aim to characterize the chemodiversity of the all botanical gardens of Switzerland. However, this ambitious objective will require us to evaluate our methodology. For this, we started by selecting two botanical collections: the Jardin Botanique de l’Université de Fribourg (JBUF) and the Jardin Botanique de Neuchâtel (JBN). This choice was made for practical reasons (these are the respective working places of the DBGI initiators) but also because these two gardens each offer their unique characteristics. On one hand the JBUF presents over 5000 species systematically organized to reflect the Angiosperm Phylogeny Group (APG) system. The JBUF researchers are specialized in conservation biology. On the other hand, the JBN presents over 2000 species organized in 8 sub-gardens. The JBN has a focus on ethnomedical plants. Below we will briefly outline the research workflow envisioned for the DBGI. The main steps have been schematized on Figure 3. The overall workflow can be divided into two main parts. One dealing with physical objects (upper part of Fig. 3) and a second one dealing with data and metadata acquired from these objects (lower part of Fig. 3).
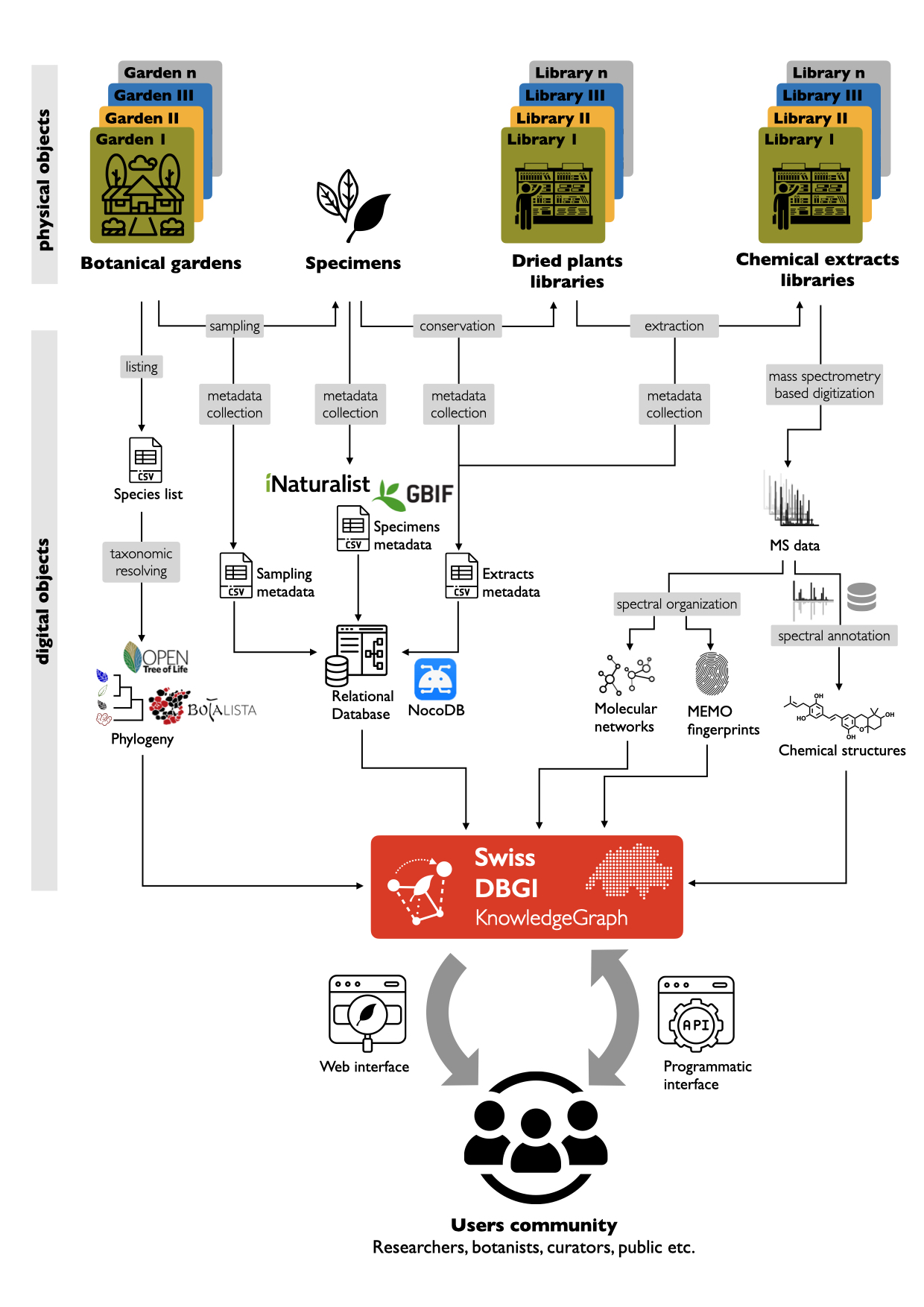 Figure 3. Overview of the DBGI main steps and data
Figure 3. Overview of the DBGI main steps and data
Regarding the physical objects, the steps are pretty simple and straightforward. Starting from a botanical garden (a living specimens collection), the aim is to sample each specimen and to build two libraries: a library of dried plant material and a library of chemical extracts. The dried plant material library will serve as a backup for extractions to be repeated and for orthogonal analysis (e.g. genetic sequencing). The chemical extracts library will be the source material for the mass-spectrometry digitization stage. This library will also be available for backups and orthogonal analysis (e.g. NMR profiling or bioassay campaigns). Complementary to herbarium, these two libraries offer an efficient way (reduced space, long term storage) to capture and conserve the chemistry of the botanical gardens.
For all operations occurring on physical objects (sampling, conservation, extraction), metadata are collected to document the experiment. For each botanical garden, data collection is made at the species level. A species is collected for each garden, curated and taxonomically resolved (using the Open Tree of Life framework) in order to be compared across gardens. The Botalista platform will also be exploited at this step. For each collected sample, data are acquired at a finer granularity (namely at the specimen level). Here we take advantage of the iNaturalist platform and app. Using a smartphone, pictures of the sampled specimen (including eventual label in the botanical gardens, sampled organ and collection label), collector identity, date and geolocation are conveniently captured at the time of the collection. This data is then automatically collected by the iNaturalist DBGI project. The data of the project can then be programmatically accessed via the iNaturalist API. All species, specimens and experimental metadata will be collected and managed through an SQL database and accessed through a NocoDB instance for a convenient tracking of the samples by the DBGI participants.
The mass-spectrometry digitization then constitutes the core of the chemical information acquisition process. We use Ultra High Performance Liquid Chromatography coupled to High Resolution Mass Spectrometry (UHPLC-HRMS) to acquire fragmentation data in an untargeted fashion. Building on our computational metabolomics expertise we then organize and annotate the acquired pool of MS data. Here we will take advantage of five central tools (four of which were conceived by us). Molecular networking [7] will serve as a basis for spectral organization. The metabolite annotation will be performed by spectral matching against a theoretical natural products spectral database [8] and via a taxonomically informed scoring process [9] fed by an open resource of natural products biological occurrences (LOTUS [10]).